-
[Java/Spring] csv파일 Parsing하여 데이터베이스에 저장하기Java, Spring 2024. 3. 14. 16:28
이전 포스팅에서 Selenium라이브러리를 활용하여 한국관광 데이터랩으로부터 비인기 여행지의 데이터를 csv파일로 저장하였다. 이제 이 많고 많은 csv파일을 파싱하여 데이터베이스에 저장하도록 해보자!
데이터베이스는 H2를 사용하고 SpringDataJpa를 통해 객체와 데이터베이스는 매핑된다. 따라서 나는 SQL을 따로 작성할 필요 없이, 엔티티 생성하고 저장하면 데이터 베이스에 해당 데이터가 저장되게 된다!
먼저 파싱 하는 클래스를 살펴보자
public class ReadLineContext<T> { Parser<T> parser; public ReadLineContext(Parser<T> parser) { this.parser = parser; } public List<T> readByLine(String directoryPath) throws IOException { //디렉토리 경로를 입력 List<T> result = new ArrayList<>(); File directory = new File(directoryPath); if (!directory.exists() || !directory.isDirectory()) { throw new IllegalArgumentException("Invalid directory path: " + directoryPath); } File[] files = directory.listFiles((dir, name) -> name.toLowerCase().endsWith(".csv")); if (files != null) { // 해당 디렉토리에서 .csv확장자 파일을 모두 불러온다. for (File file : files) { result.addAll(readFile(file)); } } return result; } private List<T> readFile(File file) throws IOException { //각 파일에서 데이터를 파싱한다. List<T> result = new ArrayList<>(); BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file), "CP949")); String line; //csv파일의 기본 인코딩은 CP949이므로 설정해주어야 한글 깨짐 현상이 없다 // 첫 번째 줄 건너뛰기 reader.readLine(); //첫번째 줄은 컬럼 명이므로 건너 뛴다 while ((line = reader.readLine()) != null) { try { result.add(parser.parse(line)); //파싱 } catch (Exception e) { System.out.printf("Error parsing line in file %s: %s\n", file.getName(), line.substring(0, Math.min(20, line.length()))); } } reader.close(); return result; } }이 클래스는 Parser 인터페이스를 가지고 있는데, 이 ReadLineContext 클래스는 제너릭이므로 생성할 때 타입을 설정해줘야 한다. 우리는 현재 비인기 관광지 객체 NotFamousPlace를 생성하여 DB에 저장할 것이므로, 제너릭 생성시 타입 매개변수를 NotFamousPlace로 주면 된다.
NotFamousPlace 클래스는 아래와 같이 생겼다. 현재는 그냥 모두 String으로 작성하였고 추후에 백엔드 개발시에는 각각
Area와 Region클래스를 따로 분리하여 만들어 관리할 것이다, 현재는 데이터 파싱이 목적이므로 간단하게 String으로만 저장한다.
public class NotFamousPlace { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String city; // 광역시/도 private String region; // 시/군/구 private String touristSpotName; // 관광지명 private String roadAddress; // 도로명주소 private String majorCategory; // 중분류 카테고리 private String subCategory; // 소분류 카테고리 private int searchCount; // 검색 건수 // 생성자 public NotFamousPlace(String city, String region, String touristSpotName, String roadAddress, String majorCategory, String subCategory, int searchCount) { this.city = city; this.region = region; this.touristSpotName = touristSpotName; this.roadAddress = roadAddress; this.majorCategory = majorCategory; this.subCategory = subCategory; this.searchCount = searchCount; } }초간단. 순위를 제외한 모든 데이터를 받아 저장할 것이다.
다음은 파싱하는 과정을 살펴보자. 이도 어렵지 않은게 .csv 파일의 row한 줄을 입력받으면 ,로 구분지어 각 데이터를 저장하는 형식이다.
public class NotFamousPlaceParser implements Parser<NotFamousPlace> { @Override public NotFamousPlace parse(String line) { String[] parts = line.split(","); if (parts.length < 8) { throw new IllegalArgumentException("Invalid input format: " + line); } try { // 순위를 건너뛰고 나머지 데이터로 NonFamousPlace 객체 생성 String city = parts[1]; String region = parts[2]; String placeName = parts[3]; String address = parts[4]; String category = parts[5]; String subCategory = parts[6]; int searchCount = Integer.parseInt(parts[7]); return new NotFamousPlace(city, region, placeName, address, category, subCategory, searchCount); } catch (NumberFormatException e) { throw new IllegalArgumentException("Invalid number format in input: " + line); } } }Parser는 인터페이스고 제너릭이다. 나중에 인기여행지도 파싱해야 하므로 그 때는 타입 파라미터로 FamousPlace를 지정할 것이다.
@RequiredArgsConstructor @Component public class ParseSaveApplication { private final NotFamousPlaceRepository notFamousPlaceRepository; public void run() { String directoryPath = "C:/Users/voslr/Downloads/소멸 위험 지역 csv 파일들"; ReadLineContext<NotFamousPlace> context = new ReadLineContext<>(new NotFamousPlaceParser()); try { List<NotFamousPlace> nonFamousPlaces = context.readByLine(directoryPath); for (NotFamousPlace place : nonFamousPlaces) { // 검색 건수가 5000 이상 10000 미만인 경우에만 저장 if (place.getSearchCount() >= 5000 && place.getSearchCount() < 10000) { System.out.println(place); // 비인기 여행지에 해당하는 NonFamousPlace 객체들을 출력 notFamousPlaceRepository.save(place); } } } catch (IOException e) { e.printStackTrace(); } } }우리의 비인기 여행지의 기준은 한국관광 데이터랩에서 제공하는 T-Map 목적지 검색 건 수
5000건 이상 10000건 미만이므로 해당 기준에 부하하는 비인기 여행지 객체만 선별하여 데이터베이스에 저장한다.
public static void main(String[] args) { ConfigurableApplicationContext context = SpringApplication.run(InstagramApplication.class, args); ParseSaveApplication parseSaveApplication = context.getBean(ParseSaveApplication.class); parseSaveApplication.run(); }위처럼 ParseSaveApplication을 빈으로 등록하고 해당 빈을 얻어 낸 다음 실행하면 아래와 같이 데이터를 출력하고 데이터베이스에도 잘 저장이 된 것을 확인할 수 있다.
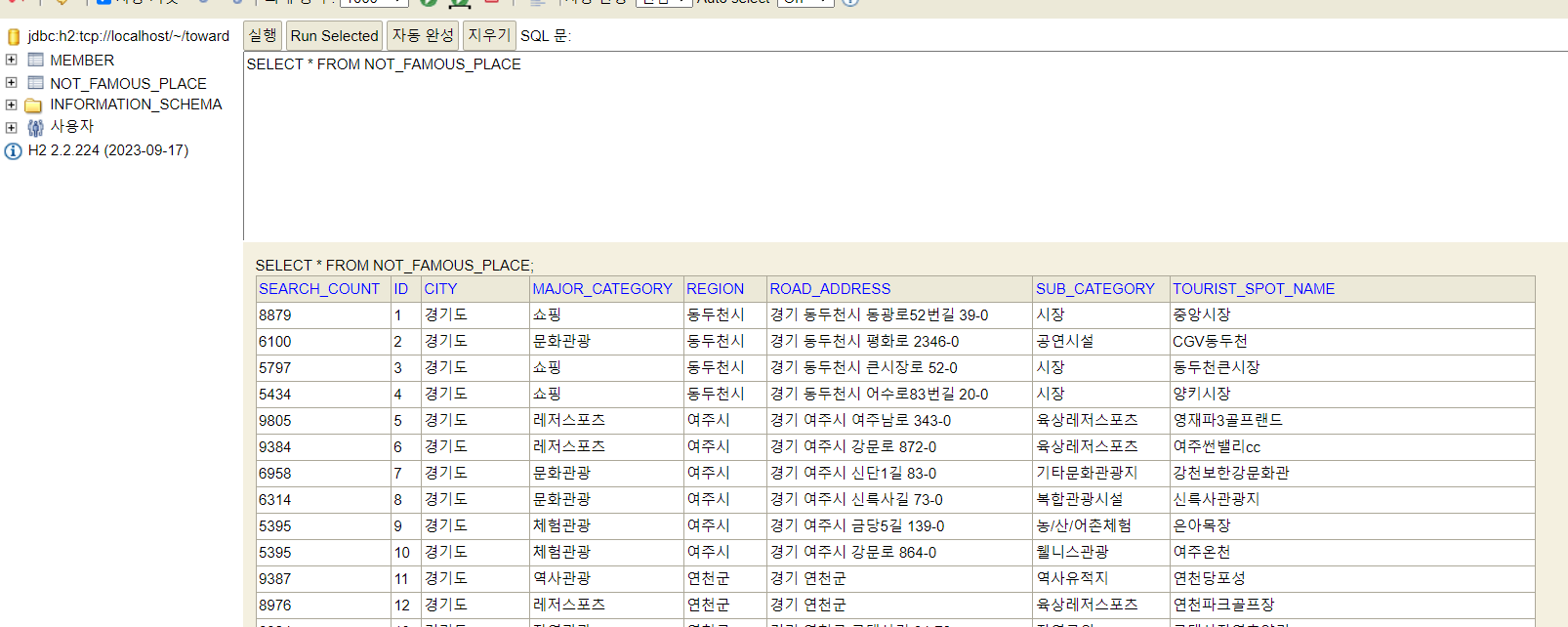
위 사진을 보면 우리 기준에 부합하는 인구 소멸지수 0.5 이하의 지역 중 T-Map 목적지 검색건수 5000건 이상 10000건 미만의 비인기 여행지들이 데이터베이스에 잘 저장 된 것을 확인할 수 있다.
다음 포스팅에서는 이렇게 얻어 비인기 여행지의 도로명 주소를 기반으로 카카오 맵 api를 활용하여 해당 여행지의 좌표(위도, 경도)를 얻어내어 보자!
'Java, Spring' 카테고리의 다른 글
[Java/Spring] 여행지의 인스타그램 해시태그 수 크롤링 (1) 2024.03.15 [Java/Spring] Selenium과 Kakao Map API를 활용하여 좌표얻기 (2) 2024.03.14 [Java/Spring] Selenium으로 데이터 크롤링하기 (1) 2024.03.14 Spring Security와 소셜 로그인 (0) 2024.03.09 HTTP 요청 메시지를 통해 클라이언트에서 서버로 데이터를 전달하는 방법 (1) 2024.01.26